Transformer LMs¶
David Strohmaier, ALTA Institute, University of Cambridge
"We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence." ~ Shazeer (2020)
Goals of this Presentation¶
- Provide an introduction to transformer language models (LMs)
- Understand basic architecture and its variations
- Understand sources of failure
- Highlight details of interest for philosophers and cognitive scientists
Generative AI¶
- Models that generate text, images, videos etc. that can be directly consumed.
- In the case of text: typically sequence-to-sequence (seq2seq)
- Model architectures that can be used for generation:
- Recurrent Neural Networks
- Diffusion models (images)
- Transformers ←today
- ...
Language Models¶
- A language model (LM) provides a probability distribution over tokens given a context
- $ p(word|context) \approx \Phi(context) $
- Old approach: Counting occurrences
- Neural language models: Around since the early 2000s
Transformer Models¶
- Introduced by Vaswani et al. (2017)
- A type of neural architecture based on the attention mechanism
- Efficient for processing and producing sequences

(image taken from Vaswani et al. (2017) and modified)


Simplifying! (cf. Geva et al. 2022 for feedforward layers)
Attention Mechanism¶
- A way to contextualise representations
- Representations are combined based on their similarity (dot-product)
- "Attention Is all You Need" (Vaswani et al. 2017)
- "Attention Is not all You Need" (Dong et al. 2021)
- "Attention is Turing Complete" (Pérez et al. 2021) ← under certain assumptions
- https://www.isattentionallyouneed.com/

Image source: Fig 3 in Bahdanau et al., 2015 https://arxiv.org/pdf/1409.0473

- Attention is used for interpretation of models.
- Some attention heads specialise on specific syntactic phenomena (e.g. Clark et al 2019, also Rogers et al. 2020).
- But it's not just importance.
Semantic Space¶
- Embeddings/activations: The vector of numbers a layer puts out
- Embeddings/activations live in a cartesian space
- Geometric interpretation of embeddings
- Space exhibits interesting regularities
- Even when reduced to 2D
- Why would that be?
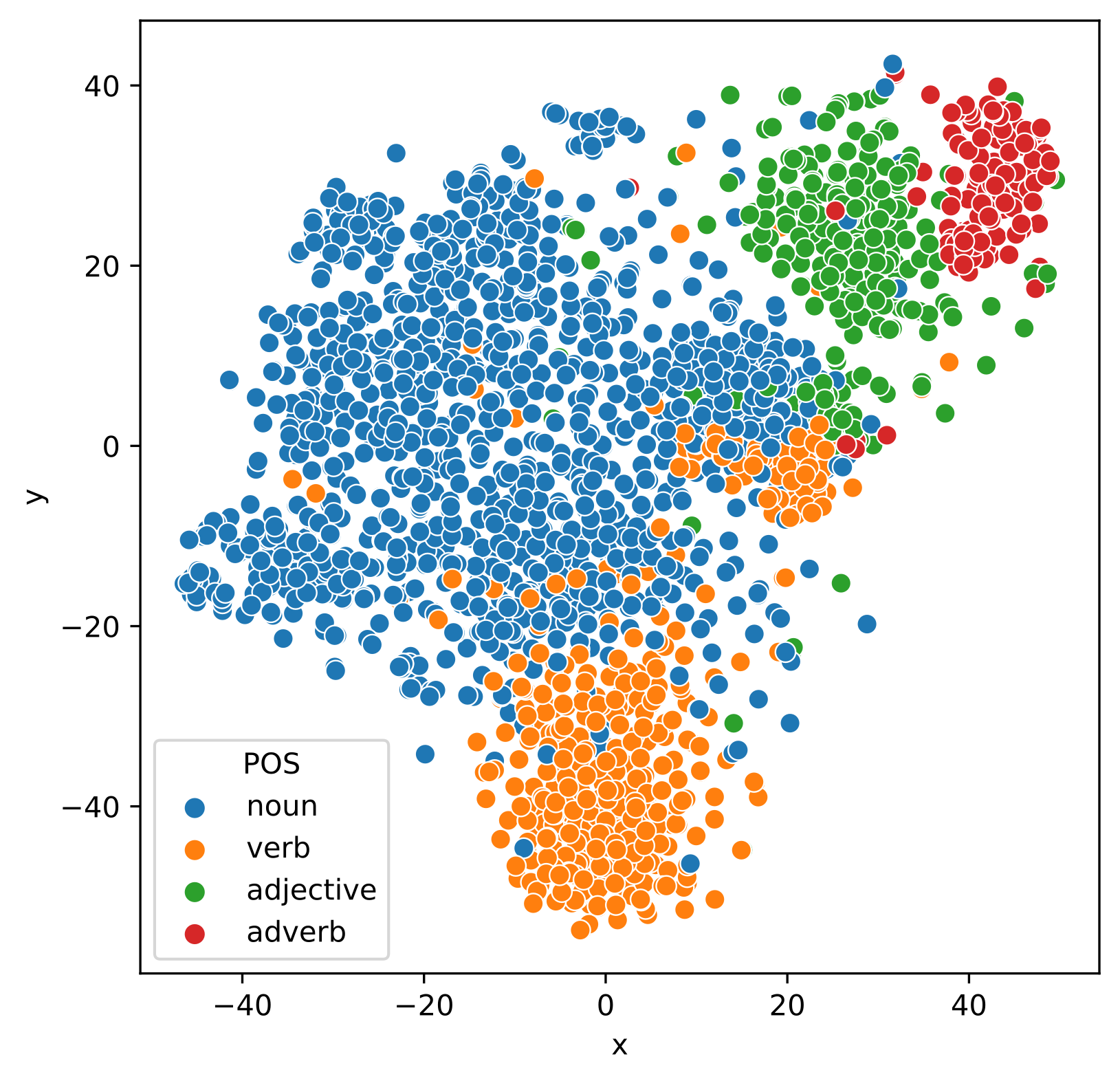
Generation¶
- How to get from state to vocabulary
- Different decoding strategies
- Sampling from the probabilitiy distribution:
- Temperature: Adjusts probability distribution
Next-word vs. masked-language-model¶
- Predict one (sub-)token at a time, left to right.
- Autoregressive language modelling (i.e. taking its own output as input)

- Predict (sub-)token anywhere in the sequence.
- Usually a single token or whole word.

- Surprising differences!
The world is everything that is the ___.¶
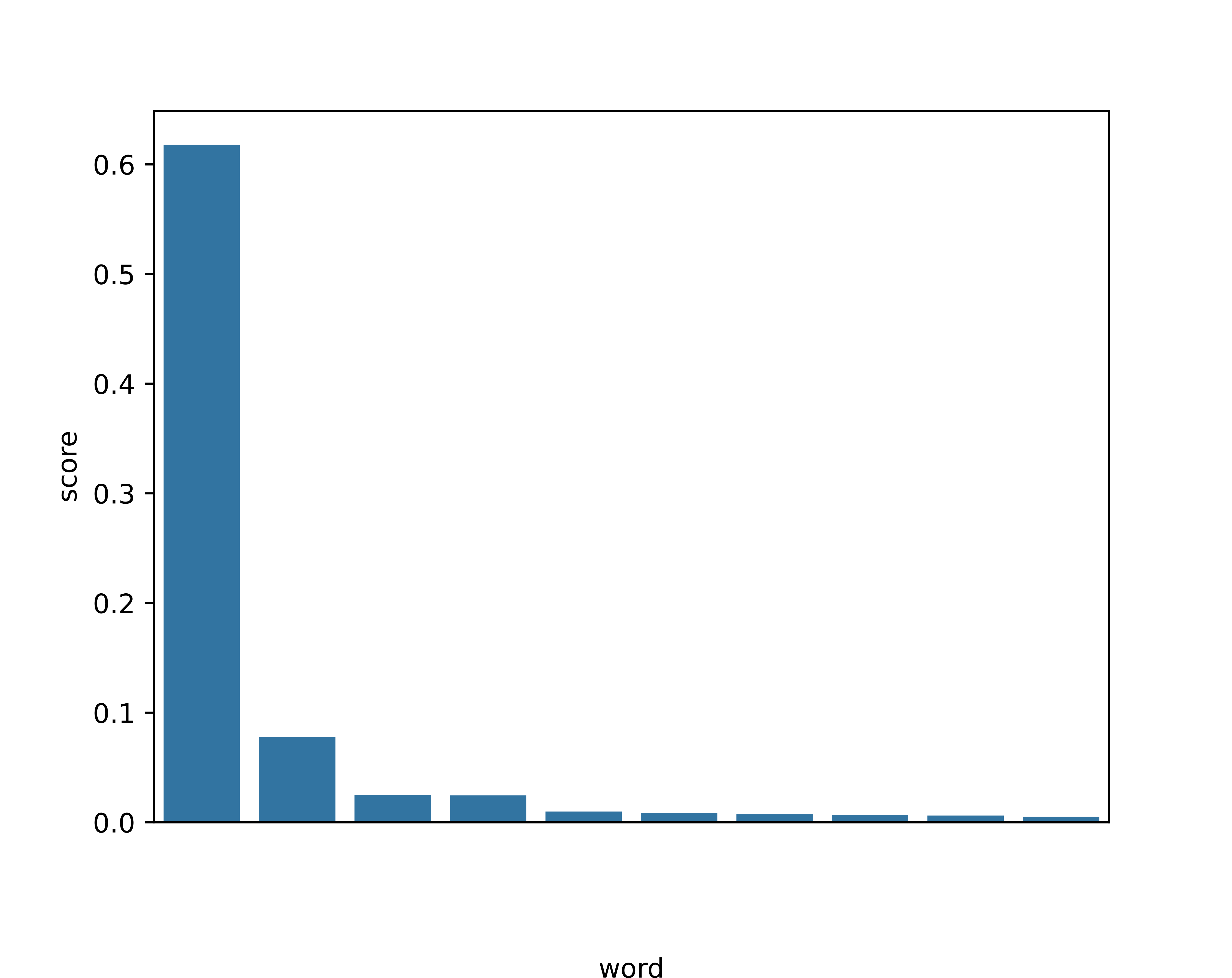
The world is everything that is the ___.¶
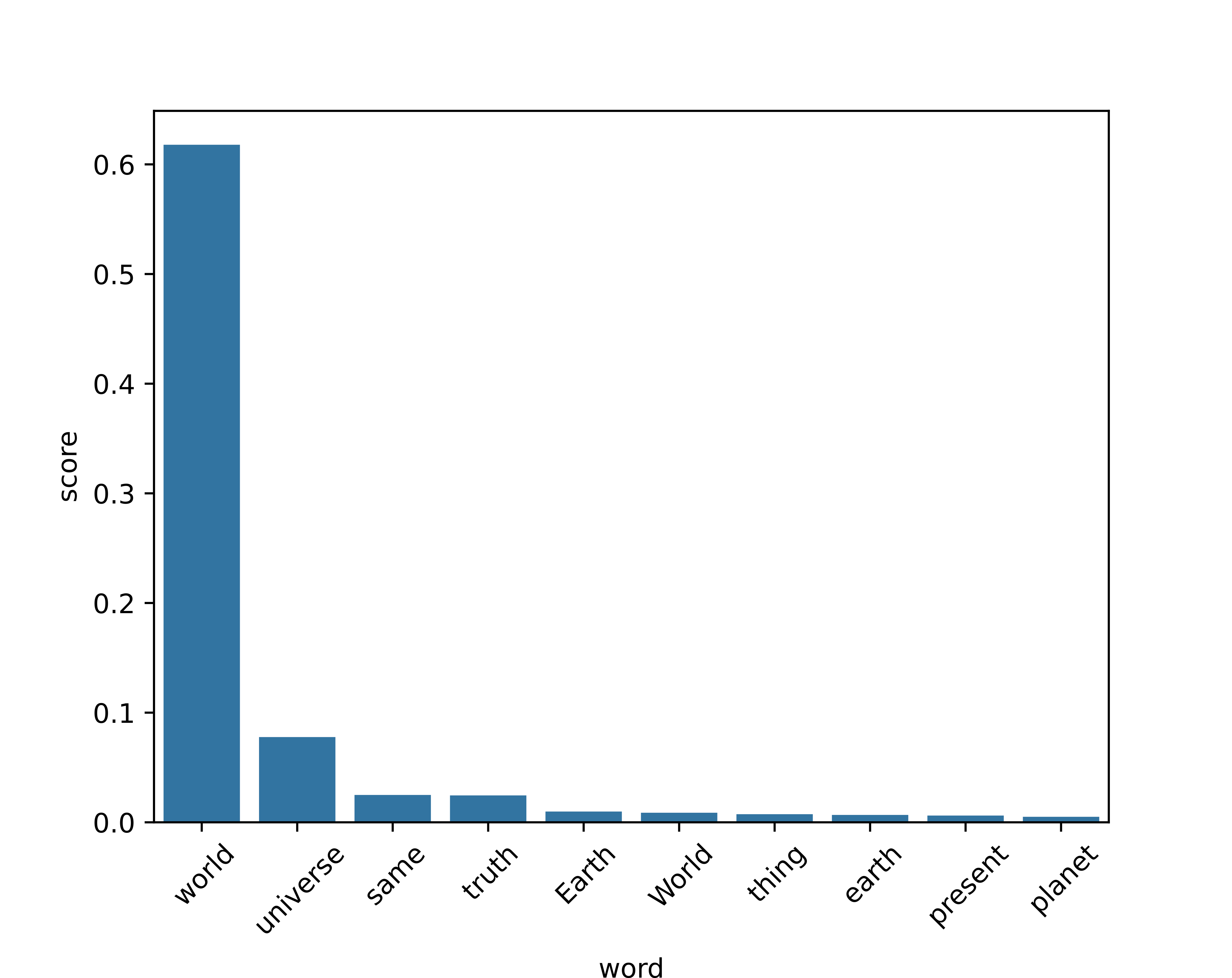
Training¶
- Large amounts of data
- In batches: predict target word (masked or next) + backpropagation
- Models might be undertrained
Backpropagation¶
- Pass batch of data through
- Calculate loss: Divergence between output and target
- Use gradient to adjust weights.
Some bold claims¶
- The neural network is not a blank slate
- Architectural bias
- Random initialisation, but which distribution?
- Lottery ticket hypothesis (Frankle & Carbin 2018)
- The training is not just gradual
- Especially when it comes to compositional skills
What I have not covered¶
- Prompting
- Hyperparameter search
- Finetuning
- RLHF
- Multi-modality
- Lots of architectural details: activation, position....
- ...
References¶
- Clark, K., Khandelwal, U., Levy, O., & Manning, C. D. (2019). What Does BERT Look at? An Analysis of BERT’s Attention. In T. Linzen, G. Chrupała, Y. Belinkov, & D. Hupkes (Eds.), Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP (pp. 276–286). Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-4828
- Dong, Y., Cordonnier, J.-B., & Loukas, A. (2021). Attention is not all you need: Pure attention loses rank doubly exponentially with depth. Proceedings of the 38th International Conference on Machine Learning, 2793–2803. https://proceedings.mlr.press/v139/dong21a.html
- Frankle, J., & Carbin, M. (2018, September 27). The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. International Conference on Learning Representations. https://openreview.net/forum?id=rJl-b3RcF7
- Geva, M., Caciularu, A., Wang, K., & Goldberg, Y. (2022). Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 30–45. https://aclanthology.org/2022.emnlp-main.3
- Pérez, J., Barceló, P., & Marinkovic, J. (2021). Attention is Turing-Complete. Journal of Machine Learning Research, 22(75), 1–35.
- Rogers, A., Kovaleva, O., & Rumshisky, A. (2020). A Primer in BERTology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics, 8, 842–866. https://doi.org/10.1162/tacl_a_00349
- Shazeer, N. (2020). GLU Variants Improve Transformer (arXiv:2002.05202). arXiv. https://doi.org/10.48550/arXiv.2002.05202
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is All you Need. Advances in Neural Information Processing Systems, 30. https://papers.nips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html